索引块分裂概念介绍
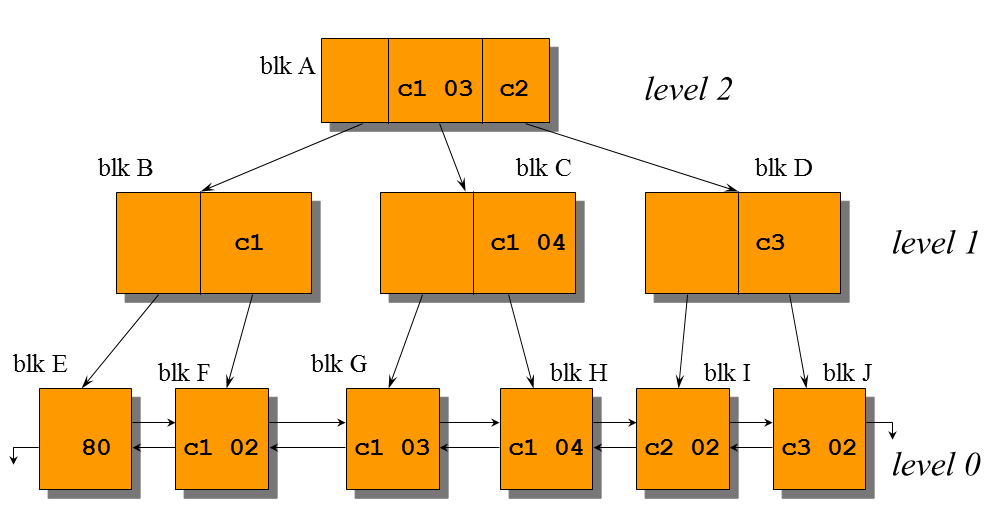
索引中的数据块 按照其作用分为:root block 根块、branch block 枝块、leaf block 叶块。
root block根块:
- 根块是索引的入口
- 对于一个索引而言根块的DBA data block address是固定的
Branch Block:
- 中间的媒介块, root指向branch ,branch指向 leaf
- 数据格式 <Child DBA> <Sseparator>
Leaf Block:
- 最低级别的索引块
- 实际数据存放在leaf blocks中
- 数据格式<Flag> <Lock> <Keydata> <Key> <NonKey>
oracle中的索引块分裂主要分成 以下几种:
- leaf node 90-10 splits
- leaf node 50-50 splits
- branch node splits
- root node splits
索引块分裂index block split 发生在 当某一个 索引块(root branch leaf) 的空闲空间不足以容纳新加入的记录时, 一般来说INSERT是引起索引块分裂的主要操作。
按照 不同的 索引块分类, 其分裂行为可以分为:
- Leaf Block Split
- Branch Block Split
- Root Block Split
按照 leaf Block Split 分裂时的行为 又可以分为:
leaf node 90-10 splits 插入到索引leaf block叶子块中的索引键是该块中最大的键值(包括块中已删除的索引键值)。 在此种情况下实施 90-10 split( 实际是 99-1 ),原叶子块仍保持99%的full, 而到另一个空的叶子块中插入该条新的最大键值记录。如图:
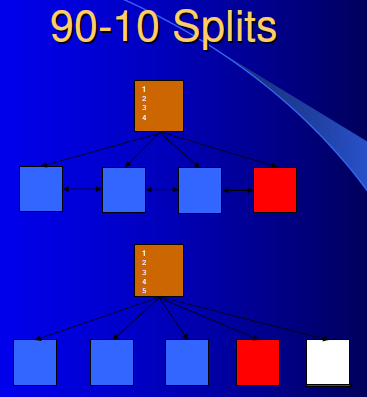
leaf node 90-10 splits 行为的次数可通过v$sysstat视图 中leaf node 90-10 splits获得,AWR中也有对应记录:

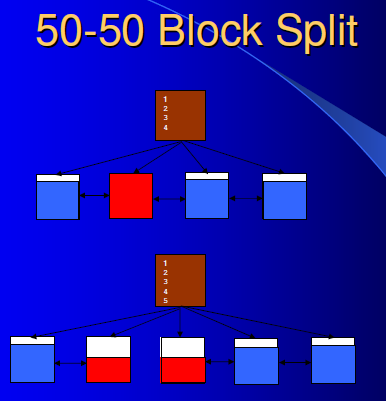
leaf node 50-50 splits 当插入到索引叶子块中的索引键值不是该块中的最大值时(包括块中已删除的索引键值), 将发生 50/50 split分裂, 这意味着有一半索引记录仍存在当前块,而另一半数据移动到新的叶子块中。
leaf node 50-50 splits 行为的次数可通过 v$sysstat视图 中的 (leaf node splits)-(leaf node 90-10 splits)获得,AWR中也是类似:
如上图中, 则在该AWR性能报告覆盖的时间中leaf node 50-50 split 发生了(1320-267)=1053 次
Branch Block 50-50 Split 由于不断的索引叶块分裂需要将新的leaf block的信息加入到branch block中,当branch block没有足够空间容纳新的记录时,又会引发branch block的 Split 。 branch block的split 是50-50的,即将一半记录移动到新的branch block中。
Branch Block 50-50 Split 行为的次数可通过 v$sysstat视图 中的branch node splits获得,AWR中也是类似:

Root Block 50-50 Split root block 根块实际是一种特殊的branch block, 当root block 50-50 split分裂发生时将分配2个新的数据块, 分裂将一半的数据移动到一个新块中,另一半数据移动到另一个新块中。 并更新原来的root block,使之指向那2个新的数据块,实际上是2个branch block了。
但是root block的数据块位置本身没有变,仍旧是原来的那个数据块。 当root block split发生时 会导致索引的高度上升。
Root Block 50-50 Split 行为的次数可通过 v$sysstat视图 中的root node splits获得,AWR中也是类似:

索引的高度 height 视乎 索引中记录的多少 、Leaf Block的数量而定,一般Height 为3~4; 举例来说当一个索引的高度为4,但是其中包含大量删除的记录,那么通过索引rebuild 往往可以降低其高度,例如从4降低到3。 假设该索引再次插入了大量的数据,造成leaf block不断分裂,最终导致root block 再次分裂, 索引高度从3再次上升到4,在这个root block split 的过程中可能短期内阻塞索引的DML维护,导致进程等待” enqueue TX: index contention” , 这在OLTP环境中是很常见的问题, 所以一般不推荐在OLTP环境中rebuild index,虽然rebuild index能够减少索引碎片回收空间 ,但由于rebuild index可能导致索引高度降级,所以对于OLTP环境的索引rebuild 需要慎重。
等待事件
当索引块分裂发生时, 负责实施分裂 split 的进程会持有 相关的队列锁enqueue TX 锁, 直到该进程完成Split操作才会释放该enqueue Tx,在这个过程中负责split的进程需要找到合适的新块并将对应的数据移动到该新块中。 若在此split过程中,有其他进程INSERT数据到该索引块中,则将进入 enq: TX – index contention等待事件,直到split结束enqueue TX被释放。
负责split的进程需要找到一个合适的新块, 其会优先寻找本index 已分配的空间中的 free block, 这些free block应当是100% free的,但是在Oracle 的segment bitmap block 中只区分 0%-25%,25%-50%, 50%-75%, 75%-100% 使用率的数据块, 即无法直接区分 0%-25%使用率的数据块中哪些是100% free的数据块, Oracle这样做的目的是 为了重用数据块,以避免过度分配空间。 当oracle发现没有可重用的数据块时才会扩展索引空间并移动分裂数据。
这个在split 过程中 寻找可复用的free block的过程称之为failed probes on index block reclamation,在正常的情况下这种找寻可复用块的过程是很快的 ,但是如果 恰好遇到 物理读缓慢或者 全局的数据块争用时,该过程可能变得很慢,这将直接导致split 变慢, 进而导致大量INSERT进程长时间等待enq: TX – index contention。
RAC中的索引块分裂
在RAC环境中 由于全局缓冲块的争用 以及 全局队列的争用, 在RAC private network 心跳网络传输存在性能瓶颈的情况下可能导致 负责split工作的进程在分裂过程中遇到 例如 gc buffer busy、gc current block busy、gc current split等等待事件,这将极大拖慢 split的速度,导致大量INSERT进程长时间等待enq: TX – index contention。
SQL> select name from v$sysstat where name like '%split%' order by name; NAME ------------------------------------------------------------------------ branch node splits index compression (ADVANCED HIGH) leaf block 90_10 splits faile index compression (ADVANCED HIGH) leaf block splits avoided index compression (ADVANCED LOW) reorg avoid split leaf node 90-10 splits leaf node splits queue splits root node splits
相关Event
10224 “index block split/delete trace”
drop table t1;
create table t1 (name varchar2(2000),nr number) pctfree 0;
create index i1 on t1(name);
alter session set events '10224 trace name context forever,level 1';
declare
i number;
begin
for i in 1..35
loop
insert into t1 values(rpad('Maclean',200,'I'),i);
end loop;
end;
/
insert into t1 values(rpad('9999999',200,'1'),9999);
insert into t1 values(rpad('9999999',200,'1'),9999);
insert into t1 values(rpad('9999999',200,'1'),9999);
oradebug setmypid
oradebug tracefile_name
*** 2013-09-02 12:07:42.632
splitting leaf,dba 0x00419669,time 12:07:42.632
kdisnew first,dba 0x0041966a,time 12:07:42.667
kdisnew using block,dba 0x0041966a,time 12:07:42.667
kdisnew first,dba 0x0041966a,time 12:07:42.667
kdisnew reject block unlink,dba 0x0041966a,time 12:07:42.667
kdisnew loop trying,dba 0x0041966b,time 12:07:42.667
kdisnew using block,dba 0x0041966b,time 12:07:42.667
Reference : <Oracle B-Tree Index Internals: Rebuilding The Truth> Richard Foote
Leave a Reply